
স্ব-হোস্টেড ইলাস্টিকসার্চের সাথে ফাইলবিট এবং লগস্ট্যাশ কীভাবে সেট আপ করবেন সে সম্পর্কে প্রচুর ব্লগ এবং ভিডিও টিউটোরিয়াল রয়েছে। কিন্তু যখন আমি ইলাস্টিক ক্লাউডের সাথে একই জিনিস সংযোগ করার চেষ্টা করেছি, তখন আমি অনেক সমস্যার সম্মুখীন হয়েছি। কারণ স্ট্যাকওভারফ্লো বা তাদের নিজস্ব ফোরামের মতো কমিউনিটি ফোরামে এটি সম্পর্কে খুব কম আলোচনা ছিল।
প্রথমত, আমরা আলোচনা করব কেন এবং কোথায় আমাদের ফাইলবিট এবং লগস্ট্যাশ দরকার। তারপর আমরা দেখব কিভাবে আমরা স্ব-হোস্টেড ইলাস্টিকসার্চ এবং ইলাস্টিক ক্লাউড উভয়ের মধ্যেই সমস্ত জিনিস সংযুক্ত করতে পারি।
কেন আমাদের ফাইলবিট এবং লগস্ট্যাশ উভয়েরই প্রয়োজন?
আমি যখন প্রথমবার এটি সেট আপ করছিলাম, তখন আমি এই দুটির মধ্যে খুব বিভ্রান্ত ছিলাম। মনে হল তারা দুজনেই একই কাজ করছে: তারা উভয়ই একটি ফাইল থেকে পড়তে পারে, JSON স্ট্রিং লগগুলিকে JSON এ রূপান্তর করতে পারে, প্রয়োজনে অতিরিক্ত ক্ষেত্র যোগ করতে পারে, ইত্যাদি। কিন্তু বেশ কয়েকটি প্রজেক্টে একা এবং একসাথে উভয়কেই ব্যবহার করার পর আমি পার্থক্য জানতে পেরেছি এবং আমি উভয়ই একসাথে ব্যবহার করতে শুরু করেছি।
আসুন আর্কিটেকচার ব্যবহার করে এটি বুঝতে পারি:
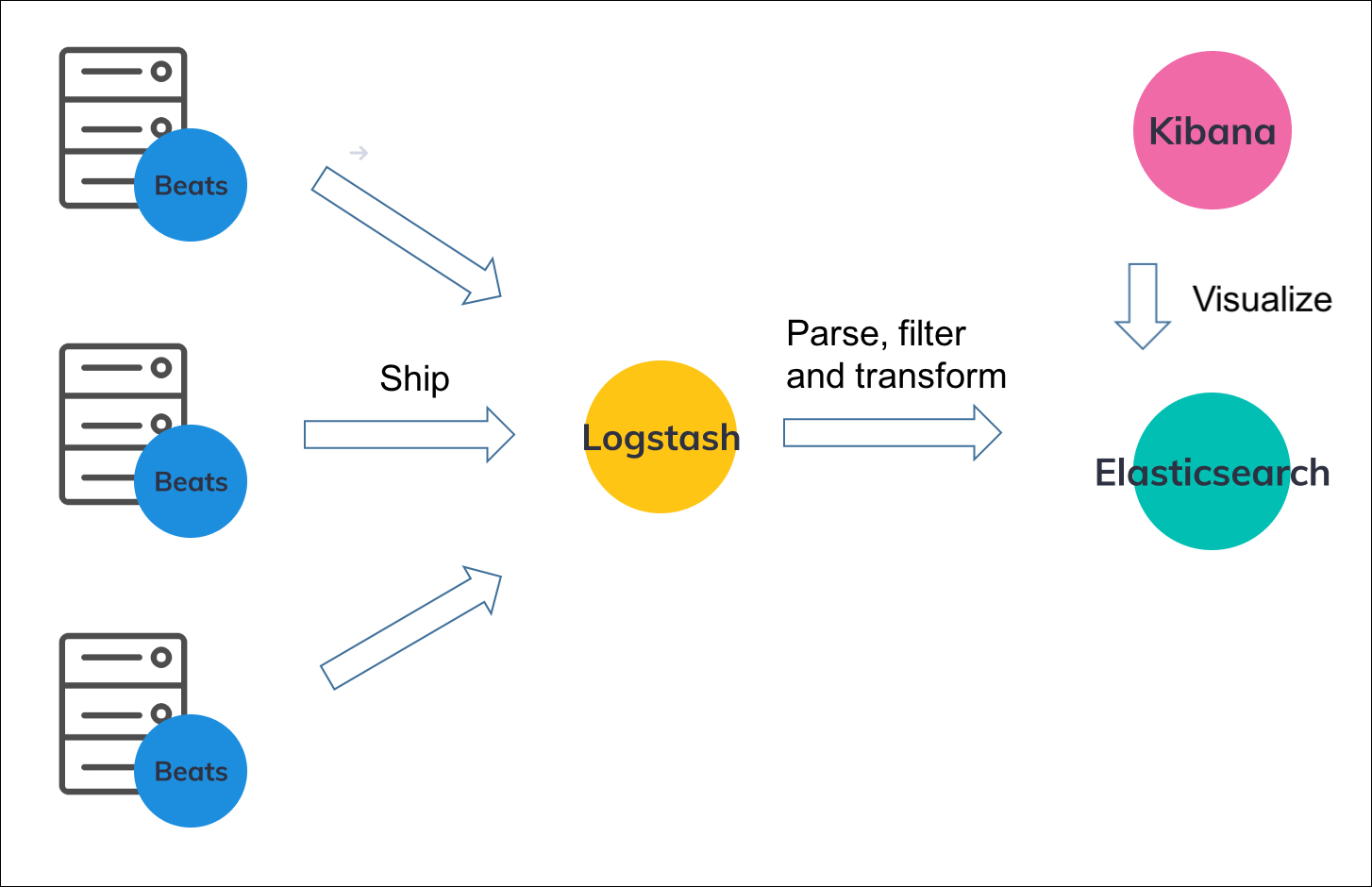
আপনি দেখতে পাচ্ছেন যে আমরা মূল সার্ভারে ফাইলবিট (বা অন্য কোনো বিট) ব্যবহার করছি যেখানে আমাদের অ্যাপ্লিকেশন লগ ফাইল(গুলি) তে লগ যোগ করছে। এই ফাইলবিট লগস্ট্যাশ সার্ভারে লগ পাঠাচ্ছে যা লগগুলিকে প্রক্রিয়া/রূপান্তর করতে ব্যবহৃত হচ্ছে এবং সেগুলিকে ইলাস্টিকসার্চে পাঠায়।
Logstash একই বা ভিন্ন সার্ভারে হতে পারে। কিন্তু আমি সাধারণত এটি একটি ভিন্ন সার্ভারে থাকতে পছন্দ করি কারণ:
- এটি ফাইলবিটের মতো হালকা নয়
- আমরা একটি একক সার্ভারে কেন্দ্রীয়ভাবে লগগুলি প্রক্রিয়া করার জন্য সমস্ত পাইপলাইন পরিচালনা করতে পারি।
Filebeat থাকার সবচেয়ে বড় সুবিধা হল, Logstash সার্ভার ডাউন থাকলেও এটি আবার চেষ্টা চালিয়ে যেতে পারে। আমি একা Logstash ব্যবহার করার সময় অতীতে কিছু লগ হারিয়ে যেতে দেখেছি। এবং অবশ্যই, ফাইলবিট বেশ হালকা।
অন্য কথায়, আমি ফাইল থেকে লগ পড়ার জন্য Filebeat ব্যবহার করি (যদিও Logstash এটি করতে পারে) এবং Logstash লগগুলিতে ডেটা যোগ, অপসারণ বা সংশোধন করতে।
যদি এটি এখনও অস্পষ্ট হয় বা আপনি এই সম্পর্কে আরও জানতে চান, আপনি পড়তে পারেন এই.
এখন এর বাস্তবায়নে ঝাঁপ দেওয়া যাক।
কিভাবে ইন্সটল করবেন?
এমনকি আপনি ইলাস্টিক ক্লাউড ব্যবহার করলেও, আপনাকে ফাইলবিট এবং লগস্ট্যাশ ইনস্টল করতে হবে। যদিও আপনি ইলাস্টিক ক্লাউডে Logstash পাইপলাইন ব্যবহার করতে পারেন। আমরা এই ব্লগে পরে আলোচনা করব.
যান ডাউনলোড পাতা এবং একই ক্রমে ইলাস্টিকসার্চ, কিবানা, লগস্ট্যাশ এবং ফাইলবিট (বিটস বিভাগ) ইনস্টল করুন। জিপ ফাইল ব্যবহার করে তাদের ইনস্টল করার নির্দেশাবলী আছে; প্যাকেজ ম্যানেজার যেমন apt, homebrew, yum, ইত্যাদি; বা ডকার। (ইলাস্টিক ক্লাউডের জন্য, আপনাকে ইলাস্টিকসার্চ এবং কিবানা ইনস্টল করতে হবে না)।
স্ব-হোস্টেড ইলাস্টিকসার্চ সেট আপ করা হচ্ছে
সফলভাবে ইলাস্টিকসার্চ ইনস্টল করার পরে, এটি চালু আছে কিনা তা দেখতে এই কমান্ডটি চালান:
curl localhost:9200এটি এই মত কিছু মুদ্রণ করা উচিত:
{
"name" : "ip-172-31-33-151",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "JPaSI3t1SK-qDXhkSapNmg",
"version" : {
"number" : "7.15.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "79d65f6e357953a5b3cbcc5e2c7c21073d89aa29",
"build_date" : "2021-09-16T03:05:29.143308416Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}আসুন মৌলিক কনফিগারেশনগুলি বুঝুন:
উবুন্টুতে, কনফিগার ফাইলগুলি সংরক্ষণ করা হয় /etc/elasticsearch ডিরেক্টরি আপনি আপনার নিজ নিজ সিস্টেমের জন্য তারা কোথায় অবস্থিত তা পরীক্ষা করতে পারেন।
দ elasticsearch.yml সেই ডিরেক্টরির ভিতরের ফাইলটি বেশ বর্ণনামূলক এবং ডিফল্টরূপে, আপনাকে একটি সাধারণ সেটআপের জন্য কিছু পরিবর্তন করতে হবে না। কিন্তু উত্পাদনের জন্য আপনাকে এই কনফিগারগুলি পরিবর্তন করতে হতে পারে।
cluster.name: ক্লাস্টারের একটি বর্ণনামূলক নাম সেট করতে।node.name: আপনার একাধিক নোড থাকলে নোডের একটি বর্ণনামূলক নাম সেট করতে।path.data: তথ্য সংরক্ষণ করতে. আপনি এটি আপনার পছন্দসই অবস্থানে পরিবর্তন করতে চাইতে পারেন।path.logs: লগ সংরক্ষণ করতে. আপনি যদি এই ডেটা হারাতে না চান তবে আপনাকে অবস্থান পরিবর্তন করতে হবে।network.host: ডিফল্টরূপে, এটি শুধুমাত্র এর মাধ্যমে অ্যাক্সেসযোগ্যlocalhost. আপনি যদি এটি একটি ভিন্ন সার্ভারে ইনস্টল করে থাকেন তবে আপনাকে এটি পরিবর্তন করতে হতে পারে৷
এছাড়াও আপনি অন্বেষণ করতে পারেন jvm.options যদি আপনি JVM হিপ সাইজ কনফিগার করতে চান তাহলে ফাইল করুন। ডিফল্টরূপে, এটি আপনার সিস্টেমে উপলব্ধ মেমরির উপর ভিত্তি করে ইলাস্টিকসার্চ দ্বারা স্বয়ংক্রিয়ভাবে কনফিগার করা হয়।
কিবানা স্থাপন করা হচ্ছে
ইনস্টলেশনের ধাপগুলি অনুসরণ করার পরে, আপনি যদি এটি আপনার স্থানীয় মেশিনে ইনস্টল করে থাকেন, তাহলে আপনি এটিতে অ্যাক্সেস করে ইনস্টলেশন পরীক্ষা করতে পারেন: localhost:5601 আপনার ব্রাউজার থেকে।
আপনি যদি AWS এর মতো ক্লাউড প্রদানকারী ব্যবহার করে এটি ইনস্টল করে থাকেন,
- আপনি পোর্ট উন্মুক্ত করতে হবে
5601নিরাপত্তা গোষ্ঠী ব্যবহার করে। - যান
/etc/kibanaডিরেক্টরি এবং খুলুনkibana.ymlকনফিগারেশন সম্পাদনা করতে। সেটserver.host: "0.0.0.0"“স্থানীয় হোস্ট” এর পরিবর্তে। - অবশেষে, আপনার ব্রাউজারে যান এবং এটি ব্যবহার করে অ্যাক্সেস করুন
<your_public_ip>:5601এবং আপনি স্বাগত পৃষ্ঠাটি দেখতে সক্ষম হবেন।
এখন kibana.yml ফাইলের বেসিক কনফিগারেশন দেখি
-
server.host: এটি কিবানা সার্ভারের সাথে আবদ্ধ হবে এমন ঠিকানা নির্দিষ্ট করে। এটি ডিফল্ট “লোকালহোস্ট” এ -
elasticsearch.hosts: আপনার সমস্ত প্রশ্নের জন্য ব্যবহার করার জন্য ইলাস্টিক সার্চ ইনস্ট্যান্সের ইউআরএল। -
যদি আপনার ইলাস্টিক সার্চ মৌলিক প্রমাণীকরণের সাথে সুরক্ষিত থাকে, তাহলে আপনাকে এইগুলি সেট করতে হবে:
elasticsearch.usernameএবংelasticsearch.password -
elasticsearch.serviceAccountToken: “পরিষেবা অ্যাকাউন্ট টোকেন” এর মাধ্যমে ইলাস্টিকসার্চে প্রমাণীকরণ করতে -
কিবানা সার্ভার থেকে ব্রাউজারে বহির্গামী অনুরোধের জন্য SSL সক্ষম করতে
-
server.ssl.enabled: SSL সক্ষম বা নিষ্ক্রিয় করতে। ডিফল্ট থেকে মিথ্যা. -
server.ssl.certificate: আপনার .crt ফাইলের পাথ -
server.ssl.key: আপনার .key ফাইলের পাথ
-
লগস্ট্যাশ সেট আপ করা হচ্ছে
একবার আপনি লগস্ট্যাশ ইনস্টল এবং সক্ষম করলে, আপনি কিছু উদাহরণ অনুসরণ করে কনফিগারেশন পরীক্ষা করতে পারেন অফিসিয়াল ওয়েবসাইট. যদি এটি আপনার প্রথমবার হয় বা আপনি ফিল্টারগুলির সাথে লড়াই করছেন, তবে ফিল্টারের ভিতরে থাকা সমস্ত কিছু সরিয়ে দিন এবং এটি চালানোর চেষ্টা করুন৷
পাইপলাইন পরীক্ষা কিভাবে?
আপনি সব কনফিগারেশন খুঁজে পেতে পারেন /etc/logstash ডিরেক্টরি (উবুন্টুর জন্য)। আপনি যদি দেখতে পান pipelines.yml ফাইল, এটি ভিতরে সমস্ত ফাইল নেয় conf.d ফোল্ডার দিয়ে শেষ .conf. আপনি একাধিক ব্যবহার করে একাধিক পাইপলাইন সেট করতে পারেন ids
আপনি যদি শুধুমাত্র একটি ফাইল পরীক্ষা করতে চান তবে আপনি এই কমান্ডটি চালাতে পারেন (উবুন্টুর জন্য):
/usr/share/logstash/bin/logstash -f filename.confআসুন ফাইলবিটের জন্য একটি মৌলিক পাইপলাইন তৈরি করি (স্ব-হোস্টেডের জন্য)
input {
beats {
port => 5044
}
}
filter {
}
output {
elasticsearch {
hosts => ("localhost:9200")
index => "applog-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}- এই পাইপলাইনটি ফাইলবিটের মতো বীট থেকে যেকোনো ইনপুটের জন্য পোর্ট 5044-এ শুনবে।
- এটি স্থানীয় ইলাস্টিকসার্চ ইনস্ট্যান্সে লগগুলি পাঠাবে
- এটি দিয়ে শুরু করে সূচকে লগ পাঠাবে
applog-এবং সেই নির্দিষ্ট লগের তারিখ দিয়ে শেষ। (যেমনapplog-2021-10-03) - দ
stdoutবিভাগ কনসোলে সবকিছু লগ ইন করে আমাদের সাহায্য করে।
ইলাস্টিক ক্লাউডের জন্য পাইপলাইন:
input {
beats {
port => 5044
}
}
filter {
}
output {
elasticsearch {
cloud_id => "My_deployment:<deployment_id>"
ssl => true
ilm_enabled => false
user => "elastic"
password => "<password>"
index => "applog-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}এই কনফিগারেশনগুলি আপনার ইলাস্টিক ক্লাউডের জন্য ঠিক কাজ করা উচিত।
কীভাবে ইলাস্টিক ক্লাউডের কেন্দ্রীভূত পাইপলাইনগুলি অন্বেষণ করবেন?
- অনুসন্ধান এবং খুলুন
Logstash Pipelinesকিবানায় বিভাগ।
- এই বিভাগে, ক্লিক করুন
Create pipeline.
- পাইপলাইন তৈরি করুন বিভাগের ভিতরে, উপরে বিশদ পেস্ট করুন এবং আপনার স্থাপনার ডেটা প্রতিস্থাপন করুন। এবং তারপর ক্লিক করুন
Create and Deploy. কনফিগারেশন এই মত কিছু দেখতে হবে:
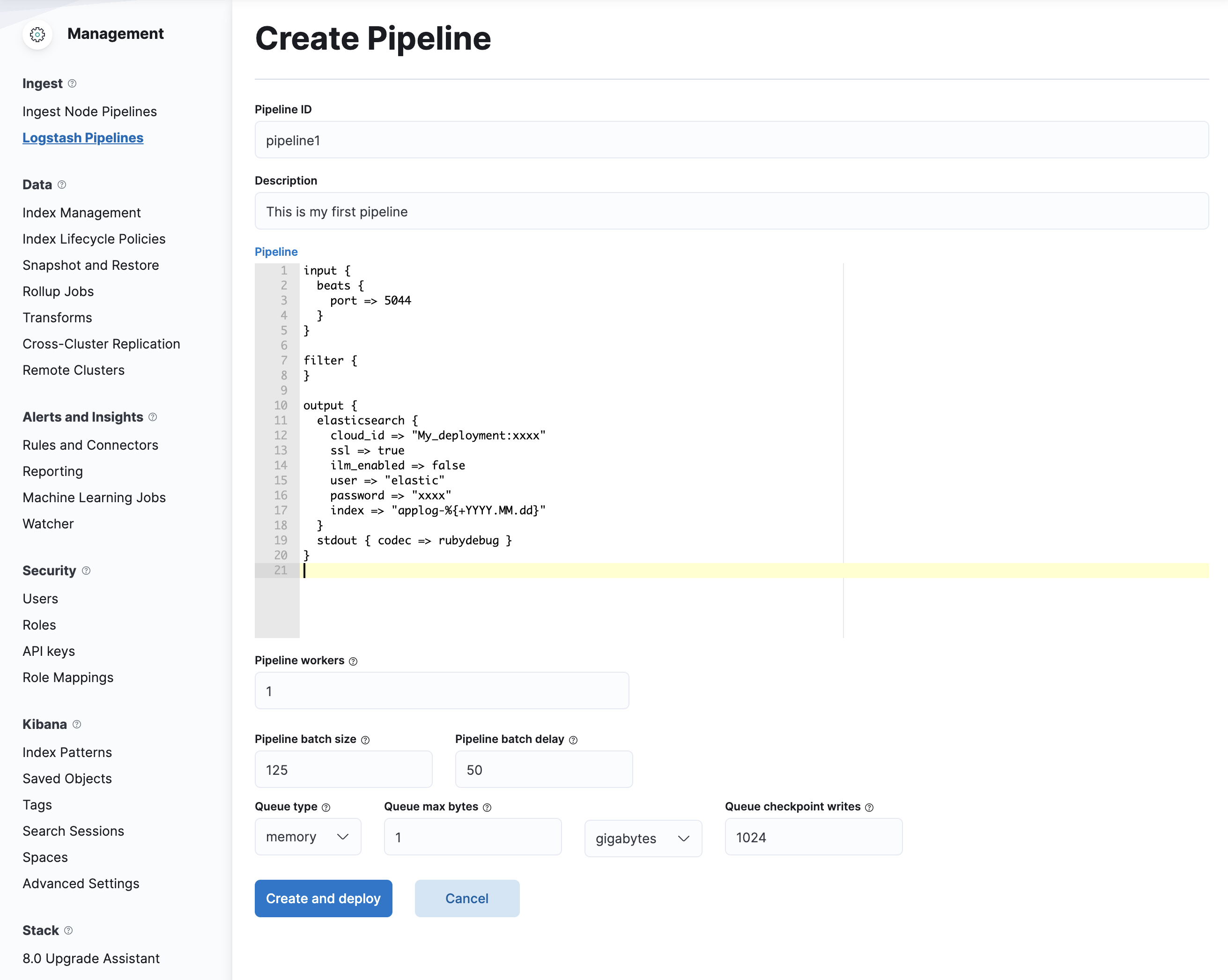
এখন এই পাইপলাইনের সাথে আমাদের Logstash সংযোগ করা যাক
দ্রষ্টব্য: আমাদের সার্ভারে চলমান একটি লগস্ট্যাশ উদাহরণ থাকা দরকার। এটি কেবল পাইপলাইনগুলিকে প্রতিস্থাপন করে এবং লগস্ট্যাশকে নয়।
- আপনার খুলুন
logstash.ymlফাইল করুন/etc/logstashডিরেক্টরি (উবুন্টু)। - অনুসন্ধান করুন এবং এই কনফিগারেশন সেট করুন:
xpack.management.enabled: true
xpack.management.pipeline.id: ("pipeline1") # ID of your pipeline
xpack.management.elasticsearch.cloud_id: management_cluster_id:xxxxxxxxxx
xpack.management.elasticsearch.cloud_auth: logstash_admin_user:passwordএই কনফিগারেশন সেট করার পরে, আপনার Logstash পরিষেবা পুনরায় চালু করুন। এটি আপনার ক্লাউড ইন্সট্যান্সের সাথে সংযুক্ত হবে এবং সেখানে সরাসরি লগ পাঠাতে শুরু করবে।
ডিফল্টরূপে, xpack.management.logstash.poll_interval সেট করা হয় 5s. এর মানে, এটি প্রতি 5 সেকেন্ডে আপনার পাইপলাইনে কোনো পরিবর্তন আছে কিনা তা পরীক্ষা করে।
ফাইলবিট সেট আপ করা হচ্ছে
এখন দ্রুত ফাইলবিটে ঝাঁপ দেওয়া যাক।
ইনস্টলেশনের পরে, খুলুন filebeat.yml ভিতরে ফাইল /etc/filebeat কনফিগারেশন পরিবর্তন করতে।
Logstash এ মৌলিক লগ পাঠাতে, আপনি এটি ব্যবহার করতে পারেন:
filebeat.inputs:
- input_type: log
enabled: true
paths:
- /var/log/elk.log
output.logstash:
hosts: ("127.0.0.1:5044")- এখানে, এটি কোন পরিবর্তন শুনছে
/var/log/elk.logফাইল - এবং এটি লগগুলিকে স্থানীয় Logstash উদাহরণে পাঠায় যা ইতিমধ্যেই পোর্টে শুনছে
5044.
কিন্তু আমি সাধারণত JSON বিন্যাসে আমার অ্যাপ্লিকেশন লগ আছে. আপনি Logstash ব্যবহার করে সেগুলি পার্স করতে পারেন তবে আসুন দেখি কিভাবে আপনি ফাইলবিট ব্যবহার করে এটি করতে পারেন।
filebeat.inputs:
- input_type: log
enabled: true
json.keys_under_root: true
paths:
- /var/log/elk.log
fileds_under_root: true
output.logstash:
hosts: ("127.0.0.1:5044")
processors:
- decode_json_fields:
fields: ("something")
process_array: true
overwrite_keys: true
add_error_key: trueএই ফাইলটি পরিবর্তন করার পরে, ফাইলবিট পরিষেবাটি পুনরায় চালু করুন। সবকিছু সঠিকভাবে সেট আপ করা হলে, এটি ঠিক কাজ করা উচিত।
আপনি JSON লগ যুক্ত করে পরীক্ষা শুরু করতে পারেন৷ /var/log/elk.log ফাইল
echo '{"hello": "world"}' >> /var/log/elk.logআসুন কিছু সময় পরে বলি, আপনি কিছু ক্ষেত্র যোগ, পরিবর্তন বা মুছে ফেলতে চাইতে পারেন। আপনি সরাসরি Logstash পাইপলাইন দ্বারা এটি করতে পারেন।
উদাহরণস্বরূপ, এই পরিবর্তনটি আপনাকে আপনার JSON লগগুলিতে একটি নতুন ক্ষেত্র যোগ করতে সাহায্য করতে পারে৷ আপনি Logstash-এর জন্য সমস্ত ফিল্টার অনুসন্ধান করতে পারেন এবং সেই অনুযায়ী ব্যবহার করতে পারেন।
filter {
mutate {
add_field => { "new" => "key" }
}
}আসুন কিবানায় এটিকে কল্পনা করি
নিশ্চিত করুন যে আপনি ইলাস্টিকসার্চে ডেটা পুশ করেছেন।
- জন্য অনুসন্ধান করুন
Index Patterns.
- ক্লিক করুন
Create index pattern. আপনি এই মত কিছু দেখতে পাবেন:
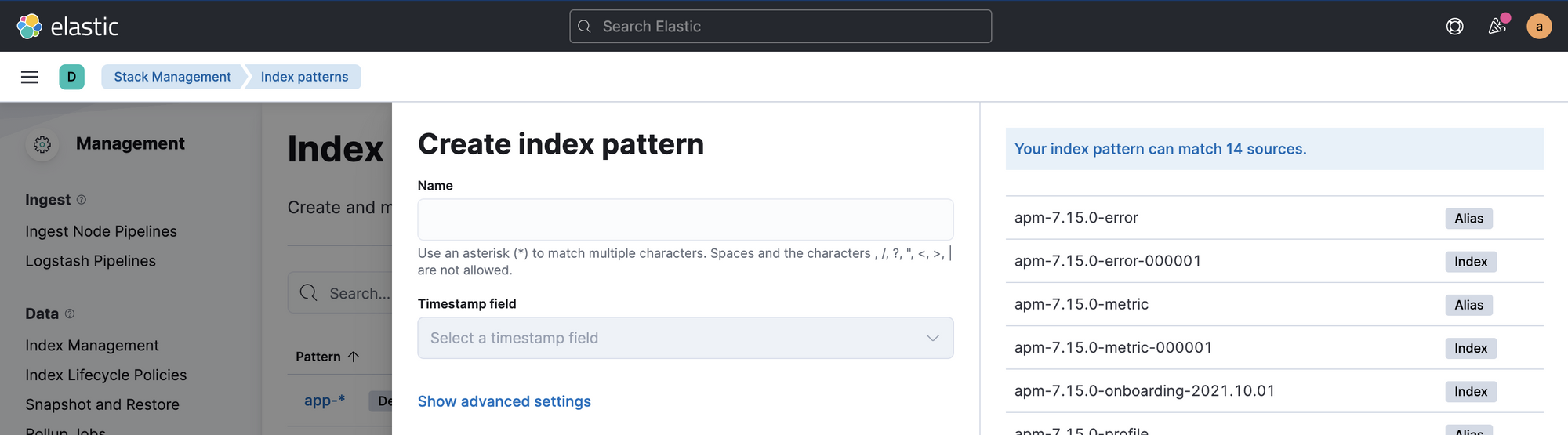
- ইন
Nameক্ষেত্র, লিখুনapplog-*এবং আপনি আপনার লগের জন্য নতুন তৈরি সূচক দেখতে পাবেন। নির্বাচন করুন@timestampজন্যTimestamp fieldএবং ক্লিক করুনCreate index pattern. - এখন যান
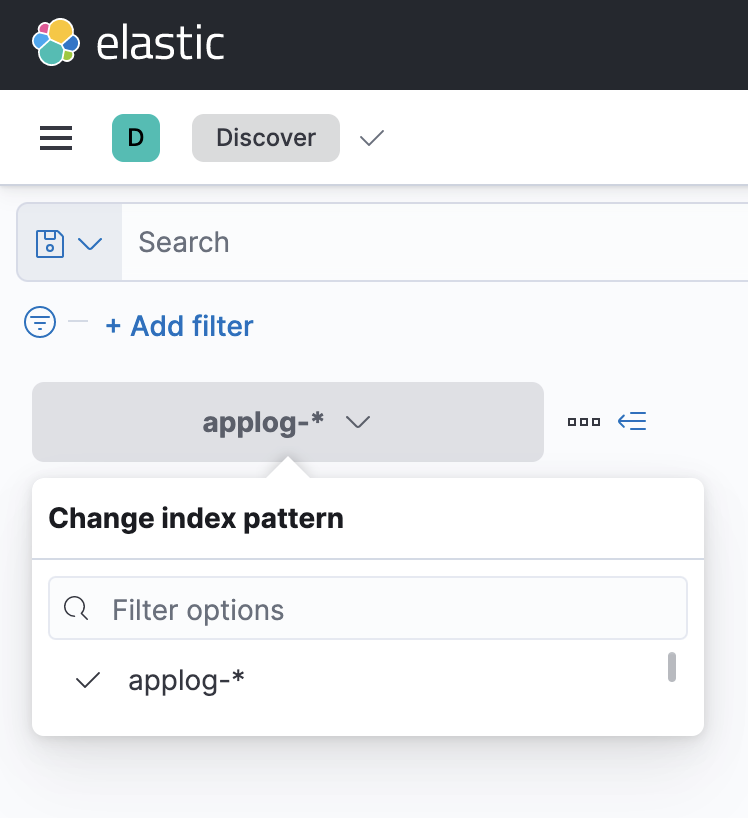
Discoverবিভাগ (আপনি যদি এটি করতে না জানেন তবে আপনি এটি অনুসন্ধান করতে পারেন) এবং আপনার সূচক প্যাটার্ন নির্বাচন করুন। আপনি লগ দেখতে সক্ষম হবেন. এছাড়াও, আপনি যদি লগগুলিকে কিছু সময় পিছনে ঠেলে দিয়ে থাকেন এবং সেগুলি দেখা যাচ্ছে না, তবে সময়সীমা পরিবর্তন করার চেষ্টা করুন।
উপসংহার
তাই আমি আমার প্রকল্পের জন্য এই কনফিগারেশন ব্যবহার করছি:
Logs inside a file -> Filebeat -> Logstash -> ElasticSearchআপনি আপনার প্রয়োজনীয়তা অনুযায়ী উপাদান পরিবর্তন/মুছে ফেলতে পারেন। আপনি যদি এই জাতীয় ব্লগগুলি পছন্দ করেন তবে দয়া করে নীচে সাবস্ক্রাইব করুন। আপনি আমাকে অনুসরণ করতে পারেন টুইটার.
