
Mozilla Connect-এ যেমন আলোচনা করা হয়েছেFirefox 130 একটি সম্পূর্ণ প্রাইভেট অন-ডিভাইস এআই মডেল ব্যবহার করে স্বয়ংক্রিয়ভাবে ছবিগুলির জন্য Alt-টেক্সট তৈরি করার জন্য একটি পরীক্ষামূলক নতুন ক্ষমতা চালু করবে। বৈশিষ্ট্যটি ফায়ারফক্সের অন্তর্নির্মিত পিডিএফ সম্পাদকের অংশ হিসাবে উপলব্ধ হবে এবং আমাদের শেষ লক্ষ্য হল স্ক্রিন রিডার সহ ব্যবহারকারীদের জন্য সাধারণ ব্রাউজিংয়ে এটি উপলব্ধ করা।
কেন Alt টেক্সট?
ওয়েব পৃষ্ঠাগুলির একটি মৌলিকভাবে সাধারণ কাঠামো রয়েছে, শব্দার্থবিদ্যা সহ যা ব্রাউজারকে তাদের নিজস্ব চাহিদা এবং পছন্দের ভিত্তিতে বিভিন্ন ব্যক্তির জন্য একই বিষয়বস্তুকে ভিন্নভাবে ব্যাখ্যা করতে দেয়। এটি আমরা যা ভাবি তার একটি বড় অংশ ওয়েবকে বিশেষ করে তোলেএবং যা ব্রাউজারকে ব্যবহারকারী এজেন্ট হিসাবে কাজ করতে সক্ষম করে, ওয়েবকে মানুষের জন্য কাজ করার জন্য দায়ী।
এটি স্ক্রিন রিডারের মতো সহায়ক প্রযুক্তির জন্য বিশেষভাবে উপযোগী, যা লোকেদের তথ্য অ্যাক্সেস এবং আদান-প্রদানে বাধা কমাতে ব্রাউজার বৈশিষ্ট্যগুলির পাশাপাশি কাজ করতে সক্ষম। স্ট্যাটিক ওয়েব পৃষ্ঠাগুলির জন্য, এটি সাধারণত সাইট থেকে খুব কম মিথস্ক্রিয়া দ্বারা সম্পন্ন করা যেতে পারে, এবং এই অ্যাক্সেসটি অনেক লোকের জন্য অত্যন্ত উপকারী হয়েছে।
কিন্তু এমনকি একটি সাধারণ স্ট্যাটিক পৃষ্ঠার জন্য নির্দিষ্ট ধরণের তথ্য রয়েছে, যেমন ছবির জন্য বিকল্প পাঠ্যসহায়ক প্রযুক্তি (যেমন বৈশিষ্ট দ্বারা প্রয়োজনীয়) দুর্ভাগ্যবশত, অনেক লেখক এটি করেন না: ওয়েব আলমানাক রিপোর্ট 2022 সালে প্রায় অর্ধেক ইমেজ অল্ট টেক্সট অনুপস্থিত ছিল।
রিমোট সার্ভারে সম্ভাব্য সংবেদনশীল ডেটা না পাঠিয়ে সম্প্রতি পর্যন্ত ব্রাউজারের পক্ষে ইমেজগুলির জন্য যুক্তিসঙ্গতভাবে উচ্চ মানের Alt পাঠ্য অনুমান করা সম্ভব নয়। যাইহোক, AI-তে সাম্প্রতিক উন্নয়নগুলি এই ধরনের চিত্র বিশ্লেষণকে দক্ষতার সাথে ঘটতে সক্ষম করেছে, এমনকি একটি CPU-তেও।
আমরা এই পদ্ধতির বৈধতা দিতে Firefox Nightly-এর PDF এডিটরের মধ্যে একটি বৈশিষ্ট্য যুক্ত করছি। যেহেতু আমরা এটিকে আরও বিকাশ করি এবং স্থাপনা থেকে শিখি, আমাদের লক্ষ্য হল ব্যবহারকারীদের জন্য এটি অফার করা যাঁরা ব্রাউজ করার সময় এটি ব্যবহার করতে চান তাদের ছবিগুলিকে আরও ভালভাবে বুঝতে সাহায্য করার জন্য যা অন্যথায় অ্যাক্সেসযোগ্য হবে না৷
ছোট ওপেন সোর্স মডেলের সাথে Alt টেক্সট তৈরি করা হচ্ছে
আমরা ছবি বর্ণনা করতে ট্রান্সফরমার-ভিত্তিক মেশিন লার্নিং মডেল ব্যবহার করছি। এই মডেলগুলি ইমেজের বিষয়বস্তু বর্ণনা করতে ভাল হচ্ছে, তবুও সীমিত সংস্থান সহ ডিভাইসগুলিতে কাজ করার জন্য যথেষ্ট কমপ্যাক্ট। একটি বড় ভাষা মডেলের মত পারফর্ম করতে পারে না ভিশন সহ GPT-4 টার্বোবা লাভাহার্ডওয়্যারের বৈচিত্র্য জুড়ে ডিভাইসে মূল্যবান অন্তর্দৃষ্টি প্রদান করার জন্য তারা যথেষ্ট সঠিক।
মডেল আর্কিটেকচার পছন্দ BLIP অথবা এমনকি ভিআইটি যেগুলি ডেটাসেটের মতো প্রশিক্ষণপ্রাপ্ত হয়েছিল কোকো (প্রসঙ্গে সাধারণ বস্তু) বা Flickr30k একটি ছবিতে বস্তু সনাক্ত করতে ভাল. যখন OpenAI এর মত একটি টেক্সট ডিকোডারের সাথে মিলিত হয় GPT-2তারা 200M বা তার কম পরামিতি সহ বিকল্প পাঠ্য তৈরি করতে পারে। একবার পরিমাপ করা হলে, এই মডেলগুলি ডিস্কে 200MB এর কম হতে পারে এবং একটি ল্যাপটপে কয়েক সেকেন্ডের মধ্যে চলতে পারে – একটি LLM-এর জন্য প্রয়োজনীয় গিগাবাইট এবং সংস্থানগুলির তুলনায় একটি বড় হ্রাস৷
উদাহরণ আউটপুট
নীচের ছবিটি (COCO ডেটাসেট থেকে টানা) দ্বারা বর্ণনা করা হয়েছে:
- ফায়ারফক্স – ভিশন ট্রান্সফরমার (ViT) ইমেজ এনকোডারের পাশাপাশি GPT-2-এর ডিস্টিলড সংস্করণ ব্যবহার করে আমাদের 182M প্যারামিটার মডেল।
- বেসলাইন মডেল – একটি সামান্য বড় ViT+GPT-2 মডেল
- মানব পাঠ্য – ডেটাসেট টীকাকার দ্বারা প্রদত্ত বিবরণ।

উভয় ছোট মডেলই একজন ব্যক্তির দ্বারা প্রদত্ত বর্ণনার তুলনায় নির্ভুলতা হারায় এবং বেসলাইন মডেল হাতের অবস্থান দ্বারা বিভ্রান্ত হয়। ফায়ারফক্স মডেল সেক্ষেত্রে কিছুটা ভালো করছে, এবং যা গুরুত্বপূর্ণ তা ক্যাপচার করে।
বিষয়গুলো যে কোনো ক্ষেত্রে ইঙ্গিতপূর্ণ হতে পারে। লক্ষ্য করুন কিভাবে ব্যক্তি অফিস সেটিংস বা কেকের চেরি সম্পর্কে লেখেননি এবং উল্লেখ করেছেন যে মোমবাতিগুলি দীর্ঘ ছিল।
যদি আমরা একটি মডেলের মত একই ইমেজ চালানো GPT-4oফলাফল অত্যন্ত বিস্তারিত:
ছবিতে দেখা যাচ্ছে একদল লোক জড়ো হয়েছে একটি কেকের চারপাশে আলোকিত মোমবাতি নিয়ে। ফোকাস কেকের উপর, যেখানে একটি লাল জেলি টপিং এবং কয়েকটি চেরি রয়েছে। অগ্রভাগে বেশ কয়েকটি আলোকিত মোমবাতি রয়েছে। ব্যাকগ্রাউন্ডে, একজন মহিলা হাসছেন, একটি ধূসর টার্টলনেক সোয়েটার পরা, এবং আরও কয়েকজনকে দেখা যেতে পারে, সম্ভবত অফিস বা ইনডোর সেটিংয়ে। ছবিটি একটি উদযাপনের পরিবেশ প্রকাশ করে, সম্ভবত একটি জন্মদিন বা একটি বিশেষ অনুষ্ঠান।
কিন্তু Alt টেক্সটে এই ধরনের বিশদ স্তর অপ্রতিরোধ্য এবং সবচেয়ে গুরুত্বপূর্ণ তথ্যকে অগ্রাধিকার দেয় না। সংক্ষিপ্ততা একমাত্র লক্ষ্য নয়, তবে এটি একটি সহায়ক সূচনা বিন্দু, এবং প্রথম খসড়াতে নির্ভুলতা বিষয়বস্তু নির্মাতাদের অনুপস্থিত প্রসঙ্গ এবং বিবরণগুলিতে তাদের সম্পাদনাগুলিকে ফোকাস করতে দেয়৷
তাই যদি আমরা LLM-কে এক-বাক্যের বিবরণের জন্য জিজ্ঞাসা করি, আমরা পাই:
একটি অফিসে একদল লোক সামনের অংশে একটি আলোকিত জন্মদিনের কেক এবং পটভূমিতে একজন হাস্যোজ্জ্বল মহিলার সাথে উদযাপন করছে৷
এটিতে আমাদের ছোট মডেলের চেয়ে আরও বিশদ রয়েছে, কিন্তু একটি সার্ভারে আপনার ছবি না পাঠিয়ে স্থানীয়ভাবে চালানো যাবে না৷
ছোট সুন্দর
ছোট মডেলের সাথে স্থানীয়ভাবে অনুমান চালানো অনেক সুবিধা প্রদান করে:
- গোপনীয়তা: সমস্ত ক্রিয়াকলাপগুলি ডিভাইসের মধ্যে রয়েছে, ডেটা গোপনীয়তা নিশ্চিত করে৷ আপনার ছবি, পিডিএফ কন্টেন্ট, জেনারেট করা ক্যাপশন বা চূড়ান্ত ক্যাপশনে আমাদের অ্যাক্সেস থাকবে না। আপনার ডেটা মডেল প্রশিক্ষণের জন্য ব্যবহার করা হবে না.
- সম্পদ দক্ষতা: ছোট মডেলগুলি ক্লাউডে উচ্চ-ক্ষমতাসম্পন্ন GPU-এর প্রয়োজনীয়তা দূর করে, সম্পদ খরচ কমায় এবং এটিকে আরও পরিবেশ বান্ধব করে।
- বর্ধিত স্বচ্ছতা: মডেলগুলির অভ্যন্তরীণ ব্যবস্থাপনা প্রশিক্ষণ ডেটাসেটগুলির সরাসরি তত্ত্বাবধানের অনুমতি দেয়, কিছু বড় ভাষা মডেলের (LLMs) তুলনায় আরও স্বচ্ছতা প্রদান করে।
- কার্বন ফুটপ্রিন্ট মনিটরিং: অভ্যন্তরীণ প্রশিক্ষণ মডেলগুলি যেমন সরঞ্জামগুলি ব্যবহার করে CO2 নির্গমনের সুনির্দিষ্ট ট্র্যাকিংয়ের সুবিধা দেয় কোড কার্বন.
- উন্নতির সহজতা: যেহেতু হার্ডওয়্যারের একক অংশে পুনঃপ্রশিক্ষণ এক দিনেরও কম সময়ে সম্পন্ন করা যেতে পারে, তাই এটি মডেলের ঘন ঘন আপডেট এবং বর্ধনের অনুমতি দেয়।
ফায়ারফক্সে স্থানীয় অনুমান একীভূত করা
অনুবাদ অনুমান আর্কিটেকচার প্রসারিত করা
ফায়ারফক্স অনুবাদ ব্যবহার করে বার্গামট দ্বারা চালিত প্রকল্প মারিয়ান সি++ অনুমান রানটাইম। রানটাইম WASM-এ কম্পাইল করা হয়েছে এবং প্রতিটি অনুবাদ কাজের জন্য একটি মডেল ফাইল আছে।
উদাহরণস্বরূপ, আপনি যদি ফ্রেঞ্চ ভাষায় ফায়ারফক্স চালান এবং একটি ইংরেজি পৃষ্ঠায় যান, ফায়ারফক্স জিজ্ঞাসা করবে আপনি এটিকে ফরাসি ভাষায় অনুবাদ করতে চান এবং অনুমান রানটাইমের পাশাপাশি ইংরেজি-টু-ফ্রেঞ্চ মডেল (~20MiB) ডাউনলোড করতে চান কিনা। এটি একটি এক-শট ডাউনলোড: অনুবাদগুলি সম্পূর্ণরূপে অফলাইনে ঘটবে একবার যখন সেই ফাইলগুলি ডিস্কে থাকবে৷
WASM রানটাইম এবং মডেল উভয়ই সংরক্ষিত হয় ফায়ারফক্স রিমোট সেটিংস পরিষেবা, যা আমাদের সেগুলিকে স্কেলে বিতরণ করতে এবং সংস্করণ পরিচালনা করতে দেয়।
অনুমান টাস্কটি একটি পৃথক প্রক্রিয়ায় চলে, যা অনুমান রানটাইম ক্র্যাশ হলে ব্রাউজার বা এর একটি ট্যাবকে ক্র্যাশ হতে বাধা দেয়।
ONNX এবং Transformers.js
আমরা এম্বেড করার সিদ্ধান্ত নিয়েছি ONNX রানটাইম ফায়ারফক্স নাইটলি এর সাথে Transformers.js লাইব্রেরি অনুবাদ আর্কিটেকচার প্রসারিত করতে বিভিন্ন অনুমান কাজ সঞ্চালন.
বার্গামটের মতো, ONNX রানটাইমের একটি WASM বিতরণ রয়েছে এবং এটি সরাসরি ব্রাউজারে চালাতে পারে। ONNX প্রকল্পটি সম্প্রতি WebGPU সমর্থন চালু করেছে, যা শেষ পর্যন্ত এই বৈশিষ্ট্যটির জন্য Firefox Nightly-এ সক্রিয় করা হবে।
Transformers.js ONNX ইনফারেন্স রানটাইমের উপরে একটি জাভাস্ক্রিপ্ট স্তর প্রদান করে, যা মডেল আর্কিটেকচারের বিশাল তালিকার জন্য অনুমান যোগ করা সহজ করে তোলে। API খুব জনপ্রিয় নকল করে পাইথন লাইব্রেরি. এটি রানটাইমে পাস করা ডেটা প্রস্তুত করার এবং আউটপুটটিকে ব্যবহারযোগ্য ফলাফলে রূপান্তর করার সমস্ত ক্লান্তিকর কাজ করে। এটি হাগিং ফেস থেকে মডেলগুলি ডাউনলোড করা এবং সেগুলি ক্যাশ করার বিষয়েও কাজ করে৷
প্রকল্পের ডকুমেন্টেশন থেকে, এইভাবে আপনি একটি পাঠ্যের উপর একটি অনুভূতি বিশ্লেষণ মডেল চালাতে পারেন:
import { pipeline } from '@xenova/transformers';
// Allocate a pipeline for sentiment-analysis
let pipe = await pipeline('sentiment-analysis');
let out = await pipe('I love transformers!');
// ({'label': 'POSITIVE', 'score': 0.999817686})
ONNX এর সাথে একটি নতুন মডেল ব্যবহার করার সময় Transformers.js ব্যবহার করা আমাদের আত্মবিশ্বাস দেয়। যদি এর আর্কিটেকচার Transformers.js ডকুমেন্টেশনে তালিকাভুক্ত করা হয়, তাহলে এটি একটি ভালো ইঙ্গিত যা আমাদের জন্য কাজ করবে।
এটিকে ফায়ারফক্স নাইটলিতে বিক্রেতা করার জন্য, আমরা Transformers.js থেকে আলাদাভাবে ONNX বিতরণ করার জন্য এর রিলিজকে কিছুটা পরিবর্তন করেছি, Node.js-সম্পর্কিত টুকরোগুলি বাদ দিয়েছি এবং সেই বিরক্তিকর eval() কলগুলিকে ONNX লাইব্রেরি জাহাজের সাথে ঠিক করেছি৷ আপনি বিল্ড স্ক্রিপ্ট খুঁজে পেতে পারেন এখানে যা সেই বিক্রেতা ডিরেক্টরিকে পপুলেট করতে ব্যবহৃত হয়েছিল।
সেখান থেকে, আমরা তার নিজস্ব প্রক্রিয়ার মধ্যে ONNX রানটাইম চালানোর জন্য অনুবাদ আর্কিটেকচারটি পুনরায় ব্যবহার করেছি এবং Transformers.js একটি কাস্টম মডেল ক্যাশে সিস্টেমের সাথে চালিত করেছি।
মডেল ক্যাশিং
Transformers.js প্রকল্প স্থানীয় এবং দূরবর্তী মডেল ব্যবহার করতে পারে এবং ব্রাউজার ক্যাশে ব্যবহার করে একটি ক্যাশিং প্রক্রিয়া রয়েছে। যেহেতু আমরা একটি বিচ্ছিন্ন ওয়েব ওয়ার্কারে অনুমান চালাচ্ছি, আমরা ফাইল সিস্টেমে অ্যাক্সেস প্রদান করতে চাই না বা ব্রাউজার ক্যাশের মধ্যে মডেলগুলি সঞ্চয় করতে চাই না। আমরা ফায়ারফক্সে মডেল হাব হিসাবে হাগিং ফেস ব্যবহার করতে চাই না এবং আমাদের নিজস্ব সার্ভার থেকে মডেল ফাইলগুলি পরিবেশন করতে চাই।
যেহেতু Transformers.js একটি কাস্টম ক্যাশের জন্য একটি কলব্যাক প্রদান করে, আমরা একটি বাস্তবায়ন করেছি নির্দিষ্ট মডেল ক্যাশিং স্তর যা আমাদের নিজস্ব সার্ভার থেকে ফাইল ডাউনলোড করে এবং IndexedDB-তে ক্যাশ করে।
প্রকল্পের বৃদ্ধির সাথে সাথে, আমরা আশা করি ব্রাউজারটি আরও মডেল সংরক্ষণ করবে, যা ডিস্কে উল্লেখযোগ্য স্থান নিতে পারে। আমরা ডাউনলোড করা মডেলগুলি পরিচালনা করতে ফায়ারফক্সে একটি ইন্টারফেস যুক্ত করার পরিকল্পনা করছি যাতে আমাদের ব্যবহারকারীরা সেগুলি তালিকাভুক্ত করতে পারে এবং প্রয়োজনে কিছু সরাতে পারে।
একটি ViT + GPT-2 মডেল ফাইন-টিউনিং
অঙ্কুর কুমার মুক্তি জনপ্রিয় মডেল ছবিগুলির জন্য Alt টেক্সট তৈরি করতে Hugging Face-এ এটা সম্পর্কে ব্লগ. এই মডেলটি Joshua Lochner দ্বারা ONNX ওজন হিসাবেও প্রকাশিত হয়েছিল যাতে এটি Transformers.js-এ ব্যবহার করা যেতে পারে, দেখুন https://huggingface.co/Xenova/vit-gpt2-image-captioning
মডেলটি একটি ভাল কাজ করছে – এমনকি যদি কিছু ক্ষেত্রে আমাদের ভাল ফলাফল ছিল https://huggingface.co/microsoft/git-base-coco – কিন্তু GIT আর্কিটেকচার এখনও ONNX কনভার্টারগুলিতে সমর্থিত নয়, এবং 200M এর কম প্যারামের সাথে, বেশিরভাগ নির্ভুলতা ভাল প্রশিক্ষণ ডেটার উপর ফোকাস করে পাওয়া যায়। তাই আমরা আমাদের প্রথম মডেলের জন্য ViT বাছাই করেছি।
অঙ্কুর ব্যবহার করেছেন google/vit-base-patch16-224-in21k ইমেজ এনকোডার এবং GPT-2 টেক্সট ডিকোডার এবং COCO ডেটাসেট ব্যবহার করে সেগুলিকে সূক্ষ্ম-টিউন করা হয়েছে, যা 120k লেবেলযুক্ত ছবির একটি ডেটাসেট।
মডেলের আকার কমাতে এবং একটু গতি বাড়াতে, আমরা GPT-2 এর সাথে প্রতিস্থাপন করার সিদ্ধান্ত নিয়েছি ডিস্টিলজিপিটি-২ — যা এর ডকুমেন্টেশন অনুযায়ী 2 গুণ দ্রুত এবং 33% ছোট।
Transformers.js-এ সেই মডেলটি ব্যবহার করা ভাল ফলাফল দিয়েছে (এ প্রশিক্ষণ কোড দেখুন GitHub – mozilla/distilvit: PDF.js-এর জন্য ইমেজ-টু-টেক্সট মডেল)
আমরা আমাদের ব্যবহারের ক্ষেত্রে মডেলটিকে আরও উন্নত করেছি আপডেট করা প্রশিক্ষণ ডেটাসেট এবং কিছু তত্ত্বাবধানে শিক্ষা আউটপুট সরলীকরণ এবং টেক্সট মডেল ইমেজ সাধারণ পক্ষপাত কিছু প্রশমিত.
PDF.js-এ Alt টেক্সট জেনারেশন
ফায়ারফক্স আমাদের ব্যবহার করে পিডিএফ-এ একটি ছবি যোগ করতে সক্ষম জনপ্রিয় ওপেন সোর্স pdf.js লাইব্রেরি:
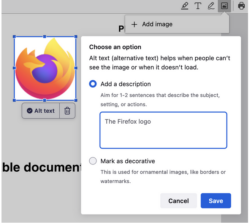
Firefox 130 থেকে শুরু করে, আমরা স্বয়ংক্রিয়ভাবে একটি Alt টেক্সট তৈরি করব এবং ব্যবহারকারীকে এটি যাচাই করতে দেব। তাই যতবারই একটি ছবি যোগ করা হয়, আমরা পিক্সেলের একটি অ্যারে পাই যা আমরা ML ইঞ্জিনে পাস করি এবং কয়েক সেকেন্ড পরে, আমরা এই চিত্রটির বর্ণনার সাথে সম্পর্কিত একটি স্ট্রিং পাই (দেখুন কোড)
ব্যবহারকারী প্রথমবার একটি ছবি যোগ করলে, মডেলটি ডাউনলোড করার জন্য তাদের কিছুটা অপেক্ষা করতে হবে (যা আপনার সংযোগের উপর নির্ভর করে কয়েক মিনিট সময় নিতে পারে) কিন্তু পরবর্তী ব্যবহারগুলি অনেক দ্রুত হবে কারণ মডেলটি স্থানীয়ভাবে সংরক্ষণ করা হবে। .
ভবিষ্যতে, আমরা পিডিএফ-এ বিদ্যমান যেকোন ছবির জন্য একটি অল্ট টেক্সট দিতে সক্ষম হতে চাই, কেবলমাত্র টেক্সট ধারণ করা ছবি ব্যতীত (এটি সাধারণত স্ক্যান করা বই ধারণকারী PDFগুলির ক্ষেত্রে হয়)।
পরবর্তী পদক্ষেপ
আমাদের Alt টেক্সট জেনারেটর নিখুঁত থেকে অনেক দূরে, কিন্তু আমরা একটি পুনরাবৃত্তিমূলক পদ্ধতি গ্রহণ করতে এবং খোলামেলা এটিকে উন্নত করতে চাই। অনুমান ইঞ্জিনটি ইতিমধ্যেই একটি নতুন হিসাবে ফায়ারফক্স নাইটলিতে অবতরণ করেছে মিলি উপাদান সঙ্গে একটি প্রাথমিক ডকুমেন্টেশন পৃষ্ঠা.
আমরা বর্তমানে এই ব্লগ পোস্টে যা বর্ণনা করেছি তার সাথে ইমেজ-টু-টেক্সট ডেটাসেট এবং মডেলের উন্নতির জন্য কাজ করছি, যা আমাদের উপর ক্রমাগত আপডেট করা হবে আলিঙ্গন মুখ পৃষ্ঠা
মডেলটি তৈরি করে এমন কোডটি গিথুবে থাকে https://github.com/mozilla/distilvit এবং মডেলটিকে উন্নত করার জন্য আমরা আমাদের দলের জন্য যে ওয়েব অ্যাপ্লিকেশন তৈরি করছি সেটি এখানে অবস্থিত৷ https://github.com/mozilla/checkvite. আমরা নিশ্চিত করতে চাই যে আমরা যে মডেল এবং ডেটাসেটগুলি তৈরি করি এবং ব্যবহৃত সমস্ত কোডগুলি সম্প্রদায়ের কাছে উপলব্ধ করা হয়৷
PDF.js-এ অল্ট টেক্সট বৈশিষ্ট্য পরিপক্ক হয়ে গেলে এবং ভালভাবে কাজ করার প্রমাণিত হলে, আমরা স্ক্রিন রিডার সহ ব্যবহারকারীদের জন্য সাধারণ ব্রাউজিংয়ে বৈশিষ্ট্যটি উপলব্ধ করার আশা করি।
ফায়ারফক্স এবং পাইথন বিশেষজ্ঞের উপর কাজ করা সিনিয়র স্টাফ মেশিন লার্নিং ইঞ্জিনিয়ার।

